I dati sintetici (o Synthetic data) sono dati generati artificialmente che replicano le caratteristiche e le proprietà dei dati reali. Questi dati vengono creati utilizzando algoritmi avanzati e simulazioni computazionali, sfruttando tecnologie come l’intelligenza artificiale generativa e l’apprendimento automatico. A differenza dei dati reali, i dati sintetici non contengono osservazioni dirette di individui o eventi specifici, garantendo così una maggiore protezione della privacy. Sono una soluzione particolarmente utile in contesti dove la disponibilità dei dati è limitata o dove è necessario rispettare rigorose normative sulla protezione dei dati. I dati sintetici possono essere utilizzati in diverse applicazioni, tra cui la formazione di modelli di machine learning, lo sviluppo di software, la ricerca scientifica e la verifica di sistemi informatici, offrendo un’alternativa sicura e flessibile ai dati reali.
Come Funzionano i Dati Sintetici?
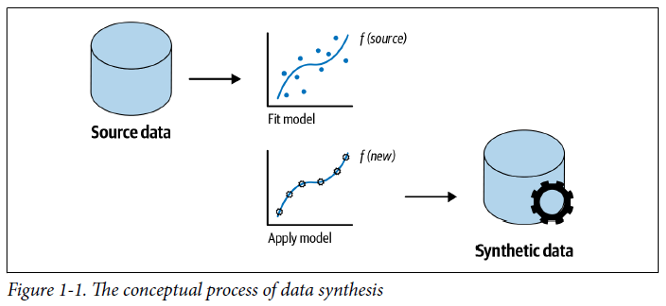
La creazione di dati sintetici coinvolge diverse metodologie principali, tra cui:
- Distribuzione Statistica: Questo metodo analizza i dati reali per identificare le loro proprietà statistiche, come distribuzioni e pattern. I Synthetic datai vengono quindi generati per rispecchiare queste proprietà, assicurando una somiglianza statistica con i dati originali.
- Generazione Basata su Modelli: Modelli di machine learning vengono addestrati su dati reali per apprenderne le caratteristiche. Questi modelli possono quindi generare dati sintetici che mantengono le stesse proprietà statistiche dei dati reali.
- Tecniche di Deep Learning: Tecniche avanzate come le reti generative avversarie (GAN) e i variational autoencoders (VAE) vengono utilizzate per creare dati sintetici complessi, inclusi immagini e dati temporali. Questi metodi sono particolarmente utili per creare dataset sintetici di alta qualità per applicazioni sofisticate.
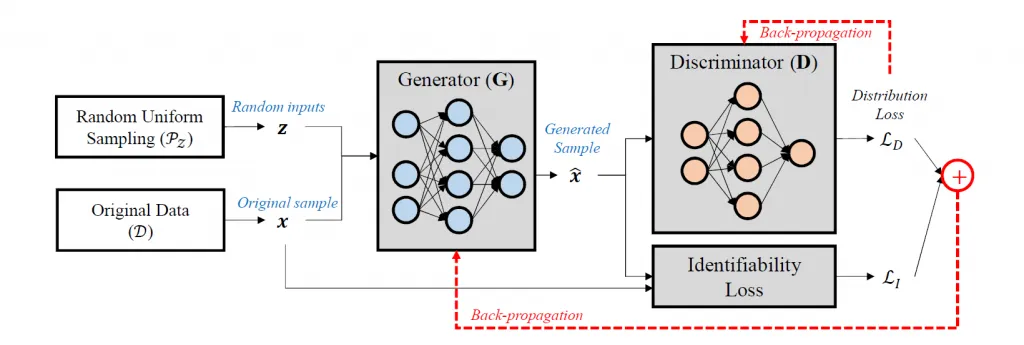
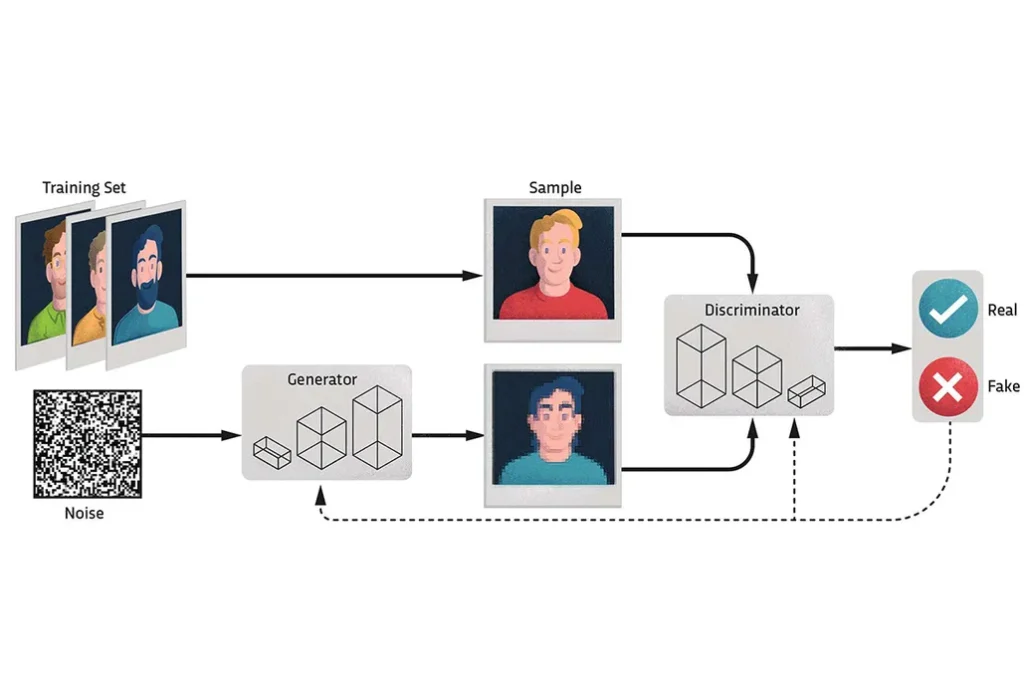
- Il processo di generazione dei dati sintetici, chiamato anche sintesi, può essere realizzato mediante diverse tecniche, come gli alberi decisionali e gli algoritmi di deep learning. I dati sintetici possono essere classificati in base al tipo di dati originali: il primo tipo utilizza dataset reali, il secondo sfrutta la conoscenza acquisita dagli analisti, mentre il terzo tipo è una combinazione di entrambi.Le Generative Adversarial Networks (GAN) rappresentano una delle tecnologie più avanzate nel deep learning, utilizzate principalmente per la generazione di immagini sintetiche. Le GAN consistono in due reti neurali che si allenano reciprocamente: la rete generatrice crea immagini sintetiche e la rete discriminatrice cerca di distinguere tra immagini reali e sintetiche. Questo processo iterativo permette di migliorare continuamente la qualità delle immagini generate.Oltre alle GAN, un’altra tecnica potente per la generazione di dati sintetici è rappresentata dai Variational Autoencoders (VAE). I VAE sono modelli generativi probabilistici che apprendono una rappresentazione compatta dei dati di input. A differenza delle GAN, che utilizzano un approccio competitivo, i VAE si basano su una combinazione di autoencoder e tecniche di inferenza variazione. I VAE mappano i dati di input in uno spazio latente di dimensione inferiore e poi campionano da questo spazio per generare nuovi dati. Questo approccio permette di controllare meglio la variabilità dei dati sintetici generati e di garantire che seguano la distribuzione dei dati originali.Entrambe le tecniche, GAN e VAE, hanno applicazioni significative in vari campi. Ad esempio, nel settore medico, possono essere utilizzate per creare dataset sintetici che rispettano la privacy dei pazienti, mentre nel settore finanziario, aiutano a generare dati per la modellazione e l’analisi quando i dati reali sono scarsi o incompleti. Inoltre, queste tecniche sono impiegate anche nella formazione di modelli di machine learning, nello sviluppo di software e nella ricerca scientifica, offrendo soluzioni flessibili e sicure per molteplici esigenze di dati
Applicazioni dei Dati Sintetici
I dati sintetici hanno una vasta gamma di applicazioni in vari settori:
Sanità: possono essere utilizzati per creare cartelle cliniche realistiche per scopi di ricerca e formazione senza compromettere la privacy dei pazienti. Consentono ai ricercatori di lavorare con dati che mantengono le proprietà statistiche dei dati reali dei pazienti senza esporre informazioni personali.
Finanza: Le istituzioni finanziarie utilizzano i dati sintetici per sviluppare e testare algoritmi per il rilevamento delle frodi, la gestione del rischio e le strategie di trading. Questi dati aiutano a rispettare le normative sulla privacy mentre si creano ambienti di test robusti.
Automotive: Nello sviluppo di veicoli autonomi, i Synthetic data vengono utilizzati per simulare scenari di guida. Questo aiuta ad addestrare algoritmi a riconoscere e rispondere a varie condizioni di guida, migliorando la sicurezza e l’affidabilità delle auto a guida autonoma.
Retail: I rivenditori utilizzano i dati sintetici per simulare il comportamento dei clienti e ottimizzare la gestione dell’inventario, le strategie di prezzo e le campagne di marketing. Questo aiuta a migliorare l’efficienza operativa e la soddisfazione dei clienti.
Machine Learning e AI: I Synthetic data sono fondamentali per addestrare e validare modelli di machine learning, specialmente quando i dati reali sono scarsi o sensibili. Consentono la creazione di grandi dataset etichettati che migliorano le prestazioni dei sistemi di intelligenza artificiale.
Importanza dei Synthetic data
L’importanza dei dati sintetici risiede nella loro capacità di affrontare diverse sfide critiche:
-
- Privacy e Conformità: I dati sintetici offrono un modo per condividere e utilizzare i dati senza violare le normative sulla privacy. Aiutano le organizzazioni a conformarsi alle leggi sulla protezione dei dati mentre continuano a analizzare e utilizzare efficacemente i dati.
- Disponibilità dei Dati: In molti casi, i dati reali possono essere scarsi o difficili da ottenere. La generazione di dati sintetici consente di creare dataset estesi, facilitando la ricerca e lo sviluppo in vari campi.
- Riduzione dei Bias: I dati sintetici possono aiutare a mitigare i bias presenti nei dati del mondo reale. Generando dataset bilanciati, è possibile creare modelli di machine learning più equi e non biasati.
- Efficienza dei Costi: La raccolta e l’etichettatura dei dati reali possono essere costosi e richiedere molto tempo. La generazione di dati sintetici è spesso più economica e veloce, fornendo un’alternativa valida per i progetti basati sui dati.
Come gestire i dati sintetici in ambito aziendale?
Nonostante i benefici, la generazione di dati sintetici presenta anche diverse sfide e insidie:
- Controllo di Qualità: Garantire la qualità e l’accuratezza dei dati sintetici è cruciale. Dati mal generati possono portare a conclusioni errate e modelli difettosi. Sono necessari processi di validazione rigorosi per mantenere alta la qualità dei dati.
- Complessità Tecnica: Il processo di generazione dei dati sintetici richiede competenze tecniche avanzate. Sviluppare algoritmi e modelli efficaci per la generazione dei dati è un compito articolato che richiede conoscenze approfondite in statistica, machine learning e data science.
- Accettazione degli Stakeholder: Convincere gli stakeholder del valore e dell’affidabilità dei dati sintetici può essere difficile. Una comunicazione chiara e la dimostrazione dei benefici sono essenziali per una più ampia accettazione.
- Considerazioni Regolatorie: Mentre i dati sintetici possono aiutare nella conformità, sollevano anche nuove questioni regolatorie. Garantire che i Synthetic data aderiscano alle leggi e alle linee guida pertinenti è necessario per evitare complicazioni legali.
Tecniche Avanzate di Generazione di Dati Sintetici
Generative Adversarial Networks (GANs) Le GANs sono composte da due reti neurali che competono tra loro: un generatore che crea dati sintetici e un discriminatore che cerca di distinguere tra dati reali e sintetici. Questo processo iterativo permette al generatore di produrre dati altamente realistici, come abbiamo già avuto modo di analizzare.
Variational Autoencoders (VAEs) I VAEs utilizzano una struttura encoder-decoder per generare dati sintetici. L’encoder trasforma i dati reali in una rappresentazione latente, mentre il decoder genera nuovi dati sintetici da questa rappresentazione. Questo approccio è utile per creare variazioni realistiche dei dati originali.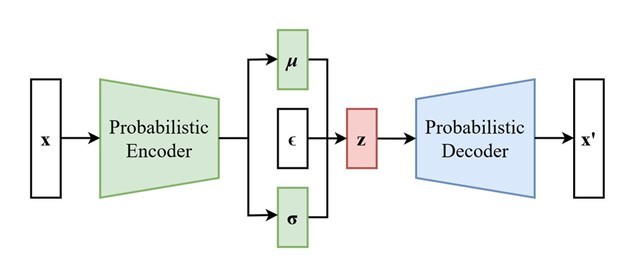 Modelli Basati su Alberi I modelli di decisione basati su alberi possono essere utilizzati per generare dati sintetici che rispettano le relazioni condizionali presenti nei dati reali. Questi modelli sono particolarmente utili per i dati strutturati e categoriali.
Modelli Basati su Alberi I modelli di decisione basati su alberi possono essere utilizzati per generare dati sintetici che rispettano le relazioni condizionali presenti nei dati reali. Questi modelli sono particolarmente utili per i dati strutturati e categoriali.
Vantaggi Specifici per Settore
Sanità
- Privacy: I dati sintetici eliminano il rischio di esposizione di dati sensibili dei pazienti, facilitando la condivisione e l’analisi dei dati.
-
Ricerca Accelerata: Consentono di creare dataset ampi e variabili per la ricerca medica, accelerando lo sviluppo di nuovi trattamenti e tecnologie.Finanza
- Conformità: Aiutano le istituzioni finanziarie a rispettare le normative sulla privacy dei dati mentre conducono analisi approfondite.
- Sviluppo di Algoritmi: Permettono di testare e migliorare gli algoritmi di rilevamento delle frodi e gestione del rischio in un ambiente controllato.
Automotive
- Sicurezza: Consentono di simulare scenari di guida per addestrare veicoli autonomi, migliorando la loro capacità di operare in condizioni reali.
- Risparmio sui Costi: Riduzione dei costi associati ai test fisici dei veicoli, permettendo simulazioni virtuali su vasta scala.
Retail
- Analisi del Comportamento del Cliente: Permette di analizzare e prevedere i comportamenti di acquisto dei clienti senza violare la privacy.
- Ottimizzazione dell’Inventario: Facilita la simulazione di diversi scenari di domanda e offerta, ottimizzando la gestione dell’inventario e le strategie di marketing.
Strumenti e Tecnologie per la Generazione di Dati Sintetici
Sintetizzatori di Dati Commerciali
- Diverse aziende offrono software specializzati nella generazione di dati sintetici, come Synthesized.io, Mostly AI, e Hazy.
- Questi strumenti forniscono interfacce user-friendly per creare dati sintetici senza richiedere competenze avanzate di programmazione.
Framework Open Source
- Esistono anche molteplici strumenti open source, come SDV (Synthetic Data Vault), Faker, e Synthia, che permettono una maggiore personalizzazione e controllo sul processo di generazione dei dati.
- Questi framework sono ideali per sviluppatori e data scientist che desiderano integrare soluzioni di dati sintetici nei loro flussi di lavoro esistenti.
Futuro dei Dati Sintetici
Adozione Crescente
- Con l’aumento delle preoccupazioni sulla privacy e la crescente complessità delle normative sulla protezione dei dati, l’adozione dei dati sintetici è destinata a crescere.
- L’industria tech sta investendo notevolmente nello sviluppo di algoritmi sempre più sofisticati per la generazione di dati sintetici, aumentando la loro qualità e affidabilità.
Integrazione con AI e Machine Learning
- La sinergia tra dati sintetici e intelligenza artificiale apre nuove frontiere nella ricerca e sviluppo. Ad esempio, i dati sintetici possono migliorare significativamente i processi di addestramento dei modelli di machine learning.
- L’uso di dati sintetici consente di affrontare problemi di data imbalance, rendendo i modelli più robusti e accurati.
Collaborazione e Condivisione dei Dati
- La generazione di dati sintetici facilita la collaborazione tra aziende e istituti di ricerca, permettendo la condivisione di dataset sintetici senza compromettere la privacy.
- Questo potrebbe portare a progressi più rapidi nella ricerca scientifica e nello sviluppo tecnologico, specialmente in settori come la sanità e l’automotive.